Building Speak's Voice Agent Platform
March 24, 2026
.png)
At Speak, we're building the future of language learning through voice-first AI. Speak helps millions of learners practice speaking through AI-powered conversations, immersive roleplays, and interactive lessons. Behind these experiences is a platform that powers voice agents capable of listening, understanding, responding, and speaking back, all with low enough latency to feel like natural conversation. Today, we'll share the unique technical challenges we faced building this platform and the decisions we made along the way.
Why we're building voice agents
Speak's core pedagogy, The Speak Method, follows a Learn → Practice → Apply loop. Voice agents power key experiences across all three phases:
Learn & Practice: Tutor Lessons
In the Learn and Practice phases, users work through structured lessons with an AI tutor. The tutor explains concepts, demonstrates phrases, and then prompts the user to speak. When the user speaks, they're talking to a voice agent that responds dynamically based on what they actually said.
If a learner says the phrase correctly, the voice agent moves on. If they make a grammar mistake, it explains the error and asks them to try again. If they ask a clarifying question ("How do you say 'of the day' again?"), it answers and guides them back to the exercise. If they go completely off-topic, it gently redirects them.
This creates a feel closer to a 1-on-1 tutoring session than a scripted lesson. The voice agent needs to handle a wide range of scenarios: pronunciation errors, incomplete responses, vocabulary mistakes, questions in the learner's native language, and background noise.
Apply: Immersive Roleplays
In the Apply phase, learners put their knowledge into action through open-ended conversations. They're placed in realistic scenarios (ordering at a café, checking into a hotel, chatting with a coworker) and have freeform conversations with voice agents playing different characters. Learners complete objectives by navigating the conversation naturally.
Unlike tutor lessons, roleplays don't have a "correct answer." The learner might accomplish the same objective in many different ways, and the voice agent needs to respond naturally to whatever they say while keeping the conversation on track.
Both experiences require voice agents that feel responsive and natural. A robotic voice or a long delay breaks the experience. And because our users are language learners, not native speakers, we face challenges that most voice AI systems don't encounter.
High-level architecture
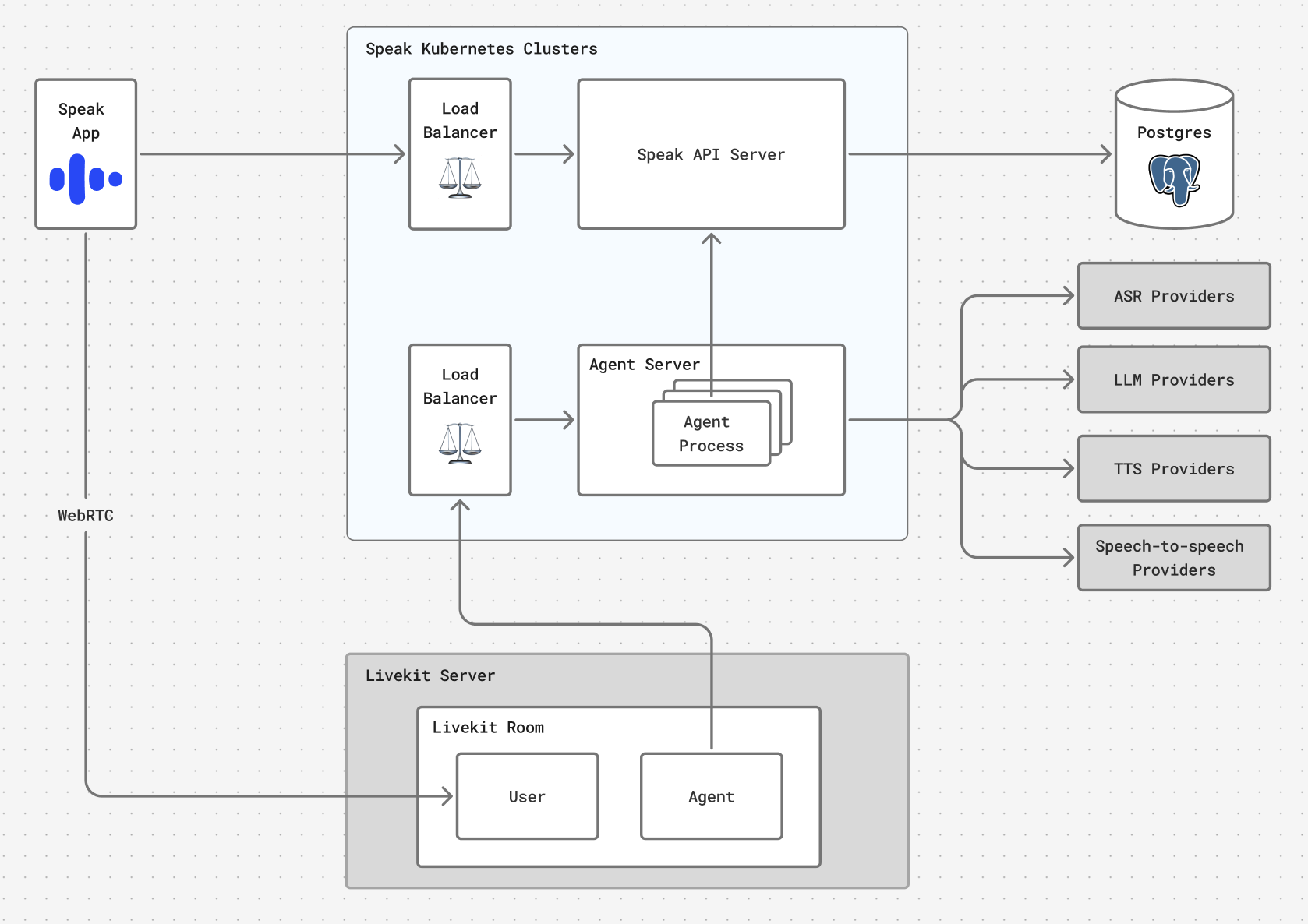
Our learners are spread across the globe, and network latency adds up across each stage of the voice pipeline. A voice agent that feels responsive in one region but sluggish in another isn't good enough. Here's how the pieces fit together.
Audio transport: WebRTC via LiveKit
Our mobile apps (iOS and Android) capture audio and play back agent responses. They connect to our backend over WebRTC, which is purpose-built for real-time audio: it handles packet loss gracefully and includes built-in echo cancellation and noise suppression. We use LiveKit Cloud for the WebRTC layer, which handles signaling, NAT traversal, and media routing, saving us from operating that infrastructure ourselves.
Voice agent servers
Voice agent servers run both the voice pipeline (cascade or speech-to-speech, discussed below) and feature-specific application logic: assessing what the learner said, evaluating learning objectives, generating hints and corrections, and deciding when to move on. These agents are built on top of the LiveKit Agents framework, which provides high-level tools for speech processing, turn-taking, and provider integration. This lets us focus on the learning experience rather than low-level media handling.
Voice agents call out to external providers for automatic speech recognition (ASR), large language model (LLM), text-to-speech (TTS), and speech-to-speech inference, and to Speak's own backend services for lesson content, conversation history, and analytics.
Global deployment
Everything runs on Speak's Kubernetes clusters deployed across multiple regions. Mobile apps connect to the nearest LiveKit Cloud edge node, which routes traffic to the closest Speak cluster. Our voice agent servers in each region connect to regionally co-located provider endpoints, so the entire pipeline, from audio capture to agent response, benefits from geographic proximity. The result: a consistently responsive experience regardless of where the learner is.
Cascade vs. speech-to-speech: Matching the pipeline to the task
When we started building our voice agent platform, we faced a fundamental architectural decision: should we use a cascade pipeline (ASR → LLM → TTS) or a native speech-to-speech model?
The answer, it turns out, is both—depending on the feature. Each architecture has distinct strengths:
Cascade gives us more control over the pipeline. For example, we can swap out individual components, add processing steps between stages, or completely modify agent responses before speaking them. Text-based LLMs also offer better instruction-following and significantly lower cost.
Speech-to-speech preserves audio properties beyond the words themselves (tone, prosody, pronunciation) and delivers lower latency since there's no ASR→LLM→TTS chain. However, the tradeoffs are less reliable instruction-following (although this is improving rapidly) and higher cost.
The key insight is that some features need properties of the audio signal that get lost in transcription. When a learner mispronounces a word, the text transcript might look correct (ASR models are trained to output valid words), but the audio itself contains information about how they said it.
Our heuristic is simple: if the feature requires understanding audio properties beyond the transcript, use speech-to-speech. Otherwise, use cascade. In practice:
- Cascade: Immersive roleplays, free-form conversations. Anywhere the meaning of what the learner said matters more than how they said it.
- Speech-to-speech: Pronunciation feedback, tutor lessons with real-time coaching on delivery, features where tone or accent matters.
When evaluating solutions for new features, we start by asking how well each approach meets the feature's requirements and where it could fall short. Then we prototype both cascade and speech-to-speech implementations, compare accuracy and speed, and model the full cost end-to-end. This hybrid architecture gives us flexibility to adopt improvements as the landscape evolves.
TTS provider selection: No one-size-fits-all
For features using the cascade pipeline, one of our most interesting findings was that no single TTS provider works well for all our use cases. We ran extensive evaluations across our language pairs and found that providers vary significantly across several dimensions:
- Language quality: Some providers excel at Asian languages but struggle with Western languages, and vice versa. Accent quality, natural prosody, and correct pronunciation of language-specific sounds all vary.
- Code-switching: Language learning often involves mixing L1 (the learner's native language) and L2 (the target language) in the same utterance. For example, a tutor explaining a Spanish phrase in English. Some providers handle this seamlessly; others produce jarring language shifts or mispronounce the embedded language entirely.
- Latency: For voice agents, TTS time-to-first-byte is critical. Some providers are not optimized for low latency and take more than a second before audio starts streaming. Others are built for real-time use cases and start streaming almost immediately. A provider with superior voice quality but high latency may simply be unusable for interactive conversations.
- Custom voices: The ability to create consistent character voices matters for immersive experiences. Provider support for voice cloning and customization varies widely.
We evaluate TTS providers per language pair and use case, sometimes running different providers even for the same feature. It adds operational complexity, but the quality difference is substantial enough to justify it.
With so many dimensions to consider and opinions on voice quality often being subjective, it's difficult to pick the right provider through analysis alone. Running experiments helped us learn faster, surface tradeoffs we wouldn't have anticipated, and make decisions based on what learners actually prefer.
Designing voice agents for language learners
Here's something most voice AI companies don't deal with: language learners pause differently than native speakers.
Standard ASR and turn detection systems typically assume that if the user pauses for 300-500ms, it signals the end of an utterance. This assumption breaks down for language learners, who pause constantly while searching for vocabulary, mentally conjugating verbs, or building confidence before continuing.
This creates two problems:
- Hurt transcription accuracy. If the system treats each pause as an utterance boundary, a single sentence gets segmented into multiple fragments. Speech recognition models perform significantly worse on these fragments than on the complete utterance.
- Premature interruptions. If we use standard voice activity detection (VAD) settings, the AI starts responding before the learner has finished speaking, creating a frustrating experience.
Our solution depends on the feature:
- Manual turn detection: For features where the user taps a button to end their turn, we treat the entire audio as a single utterance and generate one transcript for the whole recording (which may contain multiple sentences). This gives us the best transcription accuracy.
- Automatic turn detection: For features where we want a hands-free experience, we use semantic turn detection models that understand conversational context rather than relying solely on silence duration. Building turn detection models that work well for language learners is still an open problem—we're actively iterating here.
Observability: Measuring what matters
Observability is foundational to how we iterate on voice agent quality. For voice agents, that means going beyond standard infrastructure metrics and starting with what users actually experience: end-to-end agent response latency, measured from the moment a learner finishes speaking to the moment they hear the agent's voice. This is what we optimize for. But to know where to focus, we need to understand how latency accumulates across the pipeline.
When a learner finishes speaking, the clock starts. First, we need a complete transcript. We track ASR time-to-final-transcript, which measures the gap between the end of the user's turn and receipt of the final transcript. We also monitor streaming latency (how far "behind" the live transcript is relative to the audio we've sent), since this affects how quickly we can show real-time transcription, which helps learners confirm the system understood them correctly. Next, the LLM generates a response. Time-to-first-token tells us how quickly the model begins generating, which determines when the TTS stage can start working. Finally, TTS converts text to audio. Time-to-first-byte here is what determines when the learner actually hears the agent start to speak. We also track whether audio is being generated faster than real-time playback speed, which is essential for smooth streaming without stuttering.
Because we use multiple providers across language pairs, we track these metrics per provider, per language, and per region. This granularity matters — a provider that performs well in benchmarks might add unexpected latency in certain regions due to routing or degrade under load. It's also important to look beyond P50. The success rate and latency of external providers vary dramatically at the tail, so monitoring and optimizing for P95 and P99 is just as necessary. Without this level of visibility, diagnosing and resolving issues becomes much harder.
On the reliability side, we track error rates, timeout rates, and availability across both our internal services and external providers. If a provider's latency spikes or error rate crosses a threshold in a given region, we automatically shift traffic to a backup provider for that language pair. Alerts let us know when things aren't behaving as expected, so we can investigate before our learners notice.
What's next
Our realtime audio platform is the foundation for increasingly sophisticated voice experiences at Speak. We're actively working on:
- Improved turn detection: Improving semantic end-of-turn detection that understands when a language learner is actually done speaking, not just pausing to think.
- Expanding speech-to-speech use cases: As models improve at instruction-following and costs decrease, we expect to shift more features to speech-to-speech for the richer feedback it enables.
- Audio-based evals: Extending our evaluation framework to support audio inputs and outputs, enabling us to measure and improve voice agent quality more systematically
Reflections
Here's what stuck with us after building this platform.
Build for your actual users, not the demo. Standard VAD thresholds, default ASR configurations, single-provider TTS setups, all designed for native speakers in ideal conditions. The first question to ask when building voice agents for a specific domain isn't "which provider should we use?" It's "where do our users diverge from the default user these tools assume?"
Stay flexible on architecture. The voice AI landscape evolves fast. New models, providers, and capabilities emerge constantly. Committing to a single approach means betting on a specific moment in time. When a new speech-to-speech model dramatically improves instruction-following, we can shift features over incrementally. When a new TTS provider launches with great support for a language we care about, we can plug it in. Choosing the right pipeline for each feature, rather than standardizing for simplicity, gives us flexibility to adopt improvements quickly while maintaining the quality our learners expect.
Latency is a design problem, not just an infrastructure problem. We spent a lot of time optimizing our pipeline, and that matters. But some of our biggest wins came from interaction design. Manual turn detection isn't just a technical fallback; it gives learners control and eliminates the anxiety of being cut off mid-thought. Optimizing for perceived latency through thoughtful UX can matter as much as optimizing actual latency.
Building voice agents for language learners has pushed us to solve problems that don't exist in typical voice AI applications. The intersection of low-latency audio systems, multi-provider orchestration, and domain-specific pedagogy is exactly the kind of challenge we love at Speak.