Designing a High-Accuracy Speech Matching Pipeline with ASR and Phonetic Models
December 4, 2025
At Speak, our core focus is getting you speaking out loud as much as possible on your path to fluency. One key component of the Speak lesson experience is the speaking card: cards with useful phrases that you repeat out loud directly into your phone. Your words are then matched in real-time to the target line, so you can see your progress as you speak!
This particular component is powered under the hood by Automatic Speech Recognition (ASR) or transcription models combined with a custom in-house matching algorithm for pairing up the transcriptions with the words on screen. In particular, we rely on streaming ASR models that update the transcriptions every 200-300 milliseconds while the user is speaking.
We’re always working to upgrade the models and infrastructure that fuel our best-in-class ASR to keep the learning experience as seamless as possible. We’ve previously shared some of the interesting technical challenges that arise from serving our ASR models at scale — including generating transcriptions for more than 100 users per second — and today we’re sharing a peek behind the curtain at another key part of the technical puzzle: Speak’s matching algorithm.
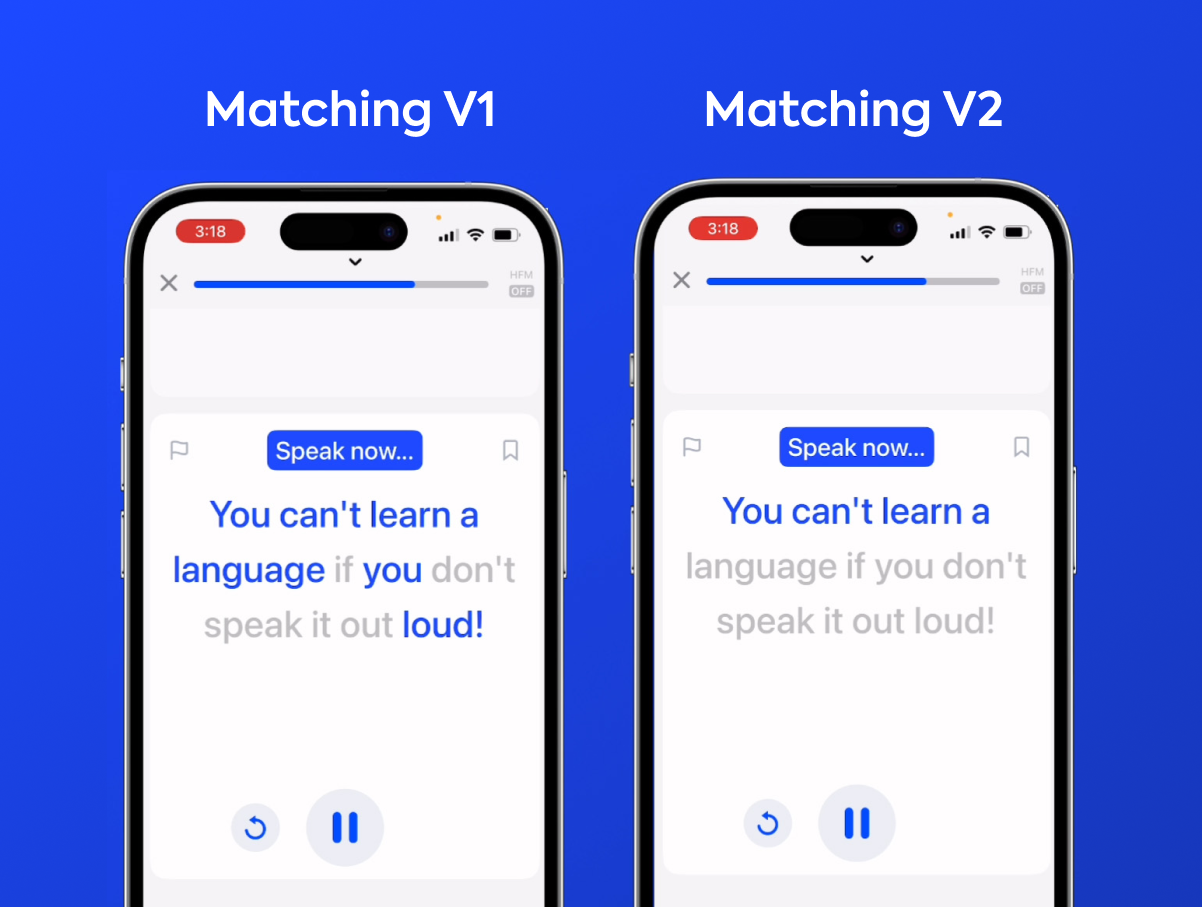
Matching v1
You can learn six languages on Speak today, all backed by custom matching algorithms tailored for the linguistic (and typographical!) quirks of each language. Before we describe how we improved the Speak lesson experience, here’s a quick overview of the problem we’re solving.
Why is matching words so difficult?
Picture this: you’re taking a lesson focused on leveling up your ability to communicate while out shopping, and it asks you to say the phrase “I would like four candles, please.” You carefully repeat it, but “four candles” stubbornly refuses to match no matter how many times you try.
What’s happening here? It’s entirely possible you’ve gotten caught in a multi-word homophone trap: you say “four candles”, and the model transcribes “fork handles”. In other words, no matter how much we level up our ASR models, achieving 100% perfect transcription accuracy is simply never possible!
Here’s another complication that’s extremely relevant to Speak: ASR models are generally trained on audio from native speakers of the language, but our users are (by definition!) learners. That means we’re transcribing audio with diverse accents, non-standard pronunciations, and inconsistent use of the subtle variations that come naturally to a native speaker, e.g. tones in Chinese, or pitch accent in Japanese.
ASR models try to convert the sounds they receive into the closest valid word in the target language assuming that those sounds were made by a native speaker of that language, which can cause all sorts of unexpected problems for learners. For example, a user who tends to pronounce the hard “th” sound in English as “d” (a very common pronunciation among our East Asian English-learners!) will find that “they” is often mistranscribed for them as “day”, making it difficult to match. Any human listening to them would immediately understand what they were saying — and that’s our goal at Speak, to get you fluent in functional, everyday language to a level that allows you to communicate naturally with native speakers of that language — but translating this nuance into an algorithm requires more than just a simple transcription model, no matter how state-of-the-art.
Some other nuances not fully captured by ASR include:
- Foreign words and loanwords: We try to incorporate a lot of useful and culturally-relevant phrases into our lessons, so users from Korea may learn how to talk in English about their love of bibimbap and American users may learn how to buy a ticket for a 프리미엄 버스 (pronounced “peurimium buseu”, literally “premium bus”) in Korea; unfortunately, foreign words and loanwords aren’t always well represented in the vocabulary of ASR models!
- Proper nouns: Learning to introduce yourself and talk about where you’re from is extremely useful, but the ASR model will generally default to the standard spelling or the language you’re speaking. So look out if you’re a French learner called Henry: chances are your name will be transcribed as “Henri”!
- Homophones: In Japanese, “箸” (chopsticks), and “端” (edge) are both pronounced as “はし” (“hashi”). In English, you’re probably familiar with “there”, “their” and “they’re”.
- Korean batchim: Korean letters are grouped into blocks representing syllables, but sometimes the final consonant of one syllable can instead be attached to the start of the next syllable without changing how the syllables are pronounced. For example, consider the target phrase 적어주세요, which our ASR transcribed as 저거주세요: the ㅇ in 어 is silent, so the ㄱ can move up from the last position of 적 to replace the ㅇ in 어, yielding 거. These two phrases sound identical, but if we compare them as strings they appear very different!
When matching, “understanding what the sentence means” and “transcribing what the actual speech is” are two different tasks. We’ve found that ASR models are typically better at the former, but the functionality needed to deliver an exceptional product experience at Speak is much closer to the latter, which is much harder to achieve!
Limitations of our current matching approach
Until now, our speaking cards relied on streaming ASR transcription combined with the “bag of words” or “word search” approach: we take all of the words in the transcription, throw them all into a bag, and then check each word in the target line to see if it appears in the bag. Repeat this multiple times per second as new transcriptions stream in from the model, and voila! You have real-time on-screen matching.
This approach allows users to repeat a “missed” word multiple times until they get it right.
However, it can also lead to intense frustration: if you’re caught in one of the transcription edge cases described above, or if your pronunciation is just off enough that the model can’t recognize it, you end up shouting the word over and over at your phone to no avail.
Another downside is that it doesn’t reinforce sentence word order, a crucial part of language learning. There’s a big difference between “man bites dog” and “dog bites man”, for example! And while most native English speakers wouldn’t be able to tell you what order adjectives should generally appear in a sentence, they would all look at you funny if you asked for “that leather French big handbag”!
Introducing… Matching v2!
Rather than focusing on bandaid solutions and incremental improvements to our ASR models, we took a step back and rethought our entire matching approach.
Phonetic Transcription
While Matching v1 did incorporate a basic form of phonetic matching, it was a text-based and language-specific solution that sat downstream of the ASR models, which meant that it couldn’t compensate for any mistakes in the transcription.
In Matching v2 we added a phonetic model alongside the standard ASR model: that is, a model that skips the “transcribe into words” step altogether and instead directly converts your speech into a sequence of language-agnostic International Phonetic Alphabet (IPA) characters. IPA is an alphabet designed to transcribe the sounds of speech directly: in theory, someone who knows IPA should be able to read it out loud even if they don’t speak the language those sounds came from. By using a phonetic model trained on a diverse multilingual dataset, this approach immediately generalizes to all of the languages we teach now and in the future.
As an example, recall the “four candles/fork handles” homophone problem discussed above. We can transcribe both of these phrases into IPA:
- four candles: /fɔɹ kændləz/
- fork handles: /fɔɹk hændləz/
Now you can see why the ASR-only approach had trouble here: the two phrases involve almost exactly the same sounds, differentiated only by the location of the word break and the subtle additional “h” sound in “fork handles” (which is technically included in the pronunciation of /k/ in “candle” as a form of aspiration). The ASR model has to pick at random which phrase to output, and will inevitably guess wrong sometimes. By contrast, the phonetic model clearly captures the similarity between the two phrases.
Back to Matching v2: with the phonetic transcription of the user’s speech in hand, we line up the IPA transcription of the target line with the output of the phonetic model using forced alignment — an algorithm that finds the mathematically optimal way to pair up the two sequences so that as many as possible of their characters line up. Finally, we use both the ASR transcription and the phonetic transcription to determine which words should be matched.
By combining ASR and phonetic transcriptions, we get the best of both worlds: the ASR model (especially one like ours that is fine-tuned specifically on non-native speech) outputs the closest valid word in the target language — which is often the word you meant to say, even if your pronunciation wasn’t quite right — and the phonetic model captures exactly the sounds that you did say, helping to handle edge cases such as loan words, homophones, slightly mispronounced words, and more.
Sequential Matching
Another big upgrade for Matching v2: bag of words is no more! You now need to speak the words of the target line in the order they appear on the screen to complete the card.
This helps reinforce the correct word order in the language you’re learning, and also contributes to a more accurate matching: by reducing the scope of matchable words from the entire target line to just a subset near the most-recently-matched word, we see a big increase in accuracy.
How fast does it need to be?
One challenge for real-time matching is the inference speed of the models. Not only do they need to be able to process audio quickly enough to keep up with a user’s speech, but we also need them to support streaming: that is, to operate iteratively on chunks of audio as they come in and return transcriptions as soon as they’re available, rather than waiting for the end of the audio file.
Traditional Kaldi-style models tend to be very slow and either cannot operate or are significantly less accurate in streaming mode. However, newer Transformer-based models (the same type of architecture that underlies LLMs like ChatGPT) can easily be run in streaming mode. Highly optimized Transformer libraries — again, fueled by the explosion in GenAI applications over the past few years — ensure lightning-fast inference speed.
We chose to customize the wav2vec2 audio model family, one of the best-performing transcription architectures, for phonetic modeling and for our matching algorithm.
This ensures we get the best of both worlds: accurate transcription and fast streaming inference.
How we measure Matching v2
There’s no industry-standard metric for measuring a matching task like this, because almost no-one except Speak does it!
The standard evaluation metric for transcription is Word Error Rate (WER) for languages that separate their text with spaces (e.g. English), and Character Error Rate (CER) for languages like Japanese and Chinese that don’t. WER/CER is one of the metrics we track to ensure that our models are performing well, but it doesn’t tell the whole story. To start, most benchmark datasets assume that the audio is from native speakers of the language, whereas our users are learners of every level of fluency and with accents from all over the world.
From Speak’s perspective, what actually matters is whether we’re correctly telling the user whether they spoke clearly enough to communicate their intent. The best way to do that is by tracking end-to-end performance of the entire matching process: that is, from the user’s speech to the match/no match highlight on the screen. Two categories of interest are:
- False negatives: when the user makes the correct sounds but the word doesn’t turn green on the screen.
- False positives: where a word turns green despite the user not having said it correctly (or at all!).
In other words, if we make our matching algorithm stricter then we see more false negatives but fewer false positives, and if we make it more lenient then we see the opposite. This tradeoff between false negatives and false positives is almost inescapable: not just here but in pretty much every classification task. However, if you replace your algorithm with a better one, it can be possible to reduce one category of error without affecting the other — the holy grail of improvements! As you’ll see below, this is what we have managed to do.
Results
As noted above, it’s a rare win when you can reduce false negatives without increasing your false positives — but here we’ve managed it! By introducing a phonetic model alongside the ASR model, we reduced false negatives by approximately 40% without making our algorithm more lenient; in other words, while holding the false positive rate steady!
This graph shows the reduction in false negatives on an internal test dataset of real user data, which was human-labelled for the highest accuracy:

In other words: we expect significantly fewer instances of users getting stuck on a hard-to-match word with Matching 2.0, while also maintaining user trust that when we highlight a word as matched it means they really did say it clearly enough to be understood!
What’s next?
We’re excited to roll out Matching v2 to all users across all languages we teach in the coming weeks. This new matching and phonetic system will serve as a more solid and extensible foundation for continuing to drive our matching performance to superhuman levels, as well as more easily launch and support new languages.
The work outlined in this post is just one example of how we’re focused at Speak on very domain-specific applied research and engineering to build the absolute best learner experience. In 2026, we plan to continue pushing on matching performance with further algorithmic improvements and model fine-tuning, as well as leverage cutting-edge AI models that generate better, faster, more accurate feedback so we can reinvent language learning.
If you’re interested in this type of applied research and software systems/infrastructure engineering that directly unlocks better & novel product experiences, we’re hiring across many technical roles. Please get in touch at: speak.com/careers