

스픽이 언어 인식 모델에서 또 한 번 이루어낸 기술적 성취를 공개합니다
스픽(Speak)의 핵심 목표는 여러분이 유창한 영어 실력을 갖추는 과정에서 가능한 한 많이 소리 내어 말하게 하는 것입니다.
스픽 수업 경험의 핵심 구성 요소 중 하나는 바로 스피킹 카드(speaking card)입니다. 유용한 문구가 적힌 카드를 보고, 사용자가 이를 휴대폰에 대고 직접 따라 말하는 기능이죠. 여러분이 말하는 단어는 화면의 목표 문장과 실시간으로 매칭되며, 이를 통해 사용자는 말하는 즉시 자신의 진척도를 확인할 수 있습니다.
이 기능은 내부적으로 자동 음성 인식(ASR, Automatic Speech Recognition) 또는 전사(transcription) 모델과, 전사된 텍스트를 화면의 단어와 짝지어주는 스픽만의 자체 매칭 알고리즘에 의해 구동됩니다. 특히, 사용자가 말하는 동안 200~300밀리초마다 전사 내용을 업데이트하는 스트리밍 ASR 모델을 활용하고 있습니다.
우리는 최고의 ASR 성능을 뒷받침하는 모델과 인프라를 지속적으로 업그레이드하여 학습 경험을 최대한 매끄럽게 만들기 위해 노력하고 있습니다.
지난 포스팅에서는 초당 100명 이상의 사용자에게 전사 기능을 제공하는 과정에서 발생하는 기술적 과제들을 공유했습니다. 이번 포스팅에서는 기술적 퍼즐의 또 다른 핵심 조각인 스픽의 매칭 알고리즘에 대한 이야기를 들려드리고자 합니다.
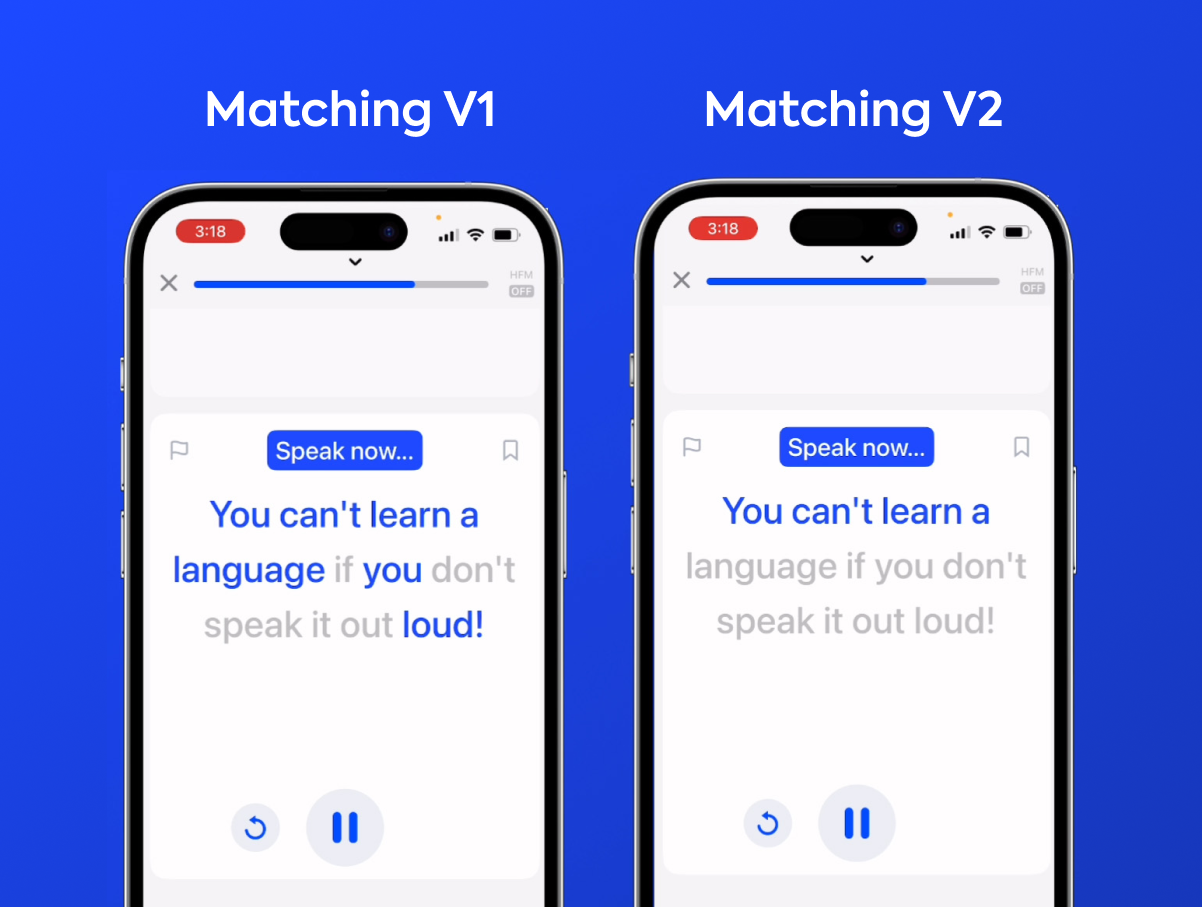
Matching v1
현재 스픽에서는 6개 국어를 배울 수 있으며, 각 언어의 언어적 특성(그리고 문자 표기상의 특성)에 맞춰 최적화된 맞춤형 매칭 알고리즘이 적용되어 있습니다. 스픽의 수업 경험을 어떻게 개선했는지 설명하기 전에, 우리가 해결하려는 문제에 대해 간단히 짚고 넘어가겠습니다.
단어 매칭은 왜 어려울까요?
상상해 보세요. 여러분이 쇼핑 중 의사소통 능력을 향상시키는 수업에서 "I would like four candles, please(양초 네 개 주세요)"라는 문장을 말해야 합니다. 여러분은 주의 깊게 따라 했지만, 아무리 반복해도 "four candles" 부분이 매칭되지 않습니다.
무슨 일이 일어난 걸까요? 여러분은 다중 단어 동음이의어(multi-word homophone)의 함정에 빠졌을 가능성이 큽니다. 여러분은 "four candles"라고 말했지만, 모델은 이를 "fork handles(포크 손잡이)"로 받아쓴 것이죠. 다시 말해, ASR 모델을 아무리 고도화하더라도 100% 완벽한 음성 인식 정확도를 달성하는 것은 불가능에 가깝습니다!
여기에 스픽에게 매우 중요한 또 다른 복잡한 문제가 있습니다. ASR 모델은 일반적으로 원어민의 음성 데이터로 훈련되지만, 우리의 사용자는 학습자라는 점입니다. 즉, 우리는 다양한 억양, 비표준 발음, 그리고 원어민에게는 자연스러운 미묘한 변형(예: 중국어의 성조나 일본어의 고저 악센트 등)을 일관성 있게 구사하지 못하는 사용자의 음성을 전사해야 합니다.
ASR 모델은 입력된 소리를 해당 언어의 원어민이 발음했다고 가정하고 가장 가까운 유효한 단어로 변환하려고 시도합니다. 이는 학습자들에게 예상치 못한 문제를 일으킬 수 있습니다.
예를 들어, 영어의 강한 "th" 발음을 "d"로 발음하는 경향이 있는 사용자(동아시아권 영어 학습자들에게 매우 흔한 현상입니다!)의 경우, "they"가 "day"로 잘못 전사되어 매칭에 실패하는 경우가 많습니다.
사람이라면 듣자마자 무슨 말을 하려는지 이해했을 것입니다. 스픽의 목표는 여러분이 원어민과 자연스럽게 소통할 수 있는 수준의 실용적인 일상 언어를 구사하게 하는 것입니다. 하지만 이러한 미묘한 뉘앙스를 알고리즘으로 구현하는 것은 아무리 최첨단의 전사 모델이라 해도 단순한 모델 하나만으로는 해결하기 어렵습니다.
ASR이 완벽하게 포착하지 못하는 다른 미묘한 부분들은 다음과 같습니다.
- 외래어와 차용어: 우리는 수업에 유용하고 문화적으로 관련된 표현을 많이 포함하려고 합니다. 한국 사용자는 비빔밥을 좋아하는 마음을 영어로 표현하는 법을 배우고, 미국 사용자는 한국에서 '프리미엄 버스(pronounced “peurimium buseu”)' 표를 예매하는 법을 배울 수 있습니다. 안타깝게도 외래어나 차용어는 ASR 모델의 어휘 목록에 잘 포함되지 않는 경우가 많습니다!
- 고유 명사: 자기소개를 하고 출신지에 대해 말하는 것은 매우 유용하지만, ASR 모델은 일반적으로 표준 철자나 현재 말하고 있는 언어의 표기법을 기본값으로 사용합니다. 만약 이름이 'Henry'인 프랑스어 학습자라면 주의해야 합니다. 여러분의 이름은 프랑스식 철자인 "Henri"로 전사될 가능성이 높기 때문입니다!
- 동음이의어: 일본어에서 "箸(젓가락)"와 "端(끝/가장자리)"는 둘 다 "はし(hashi)"로 발음됩니다. 영어에서는 "there", "their", "they're"가 익숙하실 겁니다.
- 한국어 받침(연음 현상): 한국어는 자모가 모여 음절(글자)을 이루지만, 앞 글자의 받침이 뒷글자의 초성으로 이동하여 발음되는 연음 현상이 발생합니다. 예를 들어 목표 문장이 '적어주세요'인 경우, ASR이 이를 소리 나는 대로 '저거주세요'라고 전사할 수 있습니다. ('적'의 ㄱ받침이 '어'의 ㅇ자리로 이동하여 '거'가 됨). 이 두 문구는 소리는 동일하지만, 문자열(String)로서 비교하면 매우 다르게 보입니다!
매칭에 있어서 "문장의 의미를 이해하는 것"과 "실제 발화 내용을 전사하는 것"은 서로 다른 작업입니다.
우리는 ASR 모델이 전자(의미 파악)에는 뛰어나지만, 스픽에서 탁월한 제품 경험을 제공하기 위해 필요한 기능은 후자(정확한 발화 포착)에 훨씬 더 가깝다는 것을 발견했습니다. 그리고 후자가 훨씬 더 달성하기 어렵습니다.
기존 매칭 방식의 한계
지금까지 스픽의 스피킹 카드는 스트리밍 ASR 전사와 "Bag of words(단어 주머니)" 또는 "Word Search(단어 검색)" 방식에 의존했습니다. 전사된 텍스트의 모든 단어를 하나의 '가방(bag)'에 넣고, 목표 문장의 각 단어가 그 가방 안에 있는지 확인하는 방식입니다. 모델에서 새로운 전사 내용이 들어올 때마다 초당 여러 번 이 과정을 반복하면, 화면상의 실시간 매칭이 구현됩니다.
이 방식은 사용자가 "놓친" 단어를 맞을 때까지 여러 번 반복해서 말할 수 있게 해줍니다.
하지만 이는 극심한 좌절감으로 이어질 수도 있습니다.. 위에서 설명한 예외 케이스에 걸리거나, 발음이 모델이 인식할 수 없을 정도로 조금만 빗나갈 경우, 사용자가아무리 해당 단어를 휴대폰에 대고계속해서 소리쳐 외쳐도 아무 소용 없기 때문입니다.
또 다른 단점은 언어 학습의 중요한 부분인 어순(word order)을 강화하지 못한다는 점입니다. 예를 들어 "man bites dog(사람이 개를 물다)"와 "dog bites man(개가 사람을 물다)"은 큰 차이가 있습니다!
또한 대부분의 영어 원어민은 형용사의 일반적인 어순을 문법적으로 설명하지는 못하더라도, 누군가 "that leather French big handbag"이라고 말하면 이상하게 쳐다볼 것입니다! (역주: 올바른 어순은 "that big French leather handbag"입니다.)
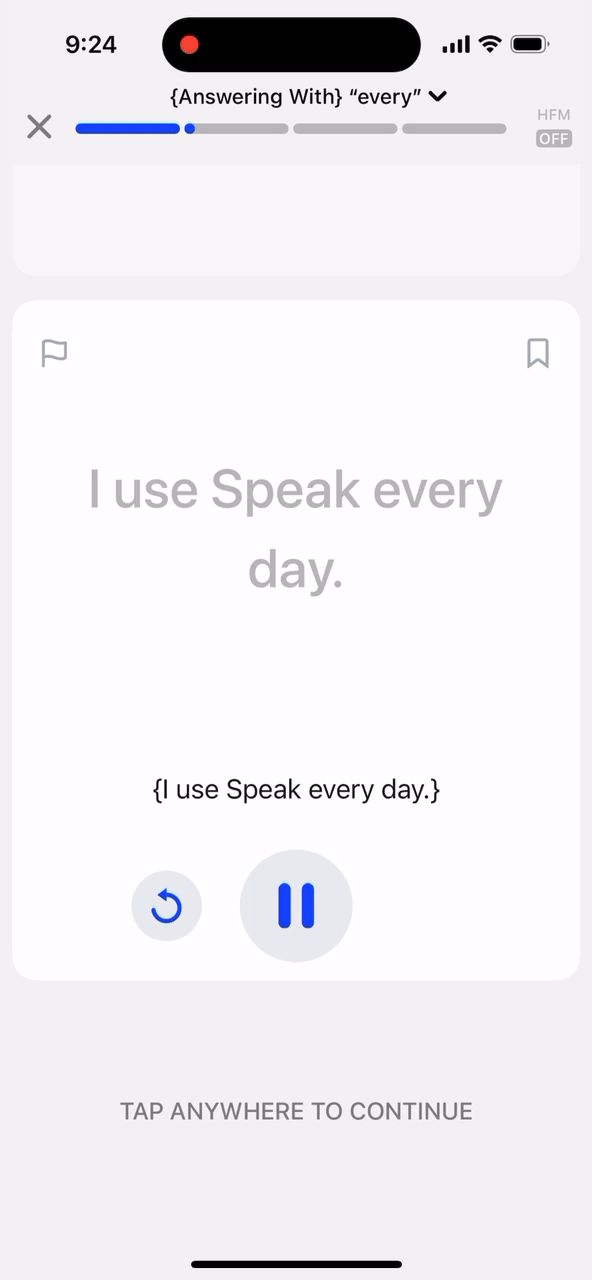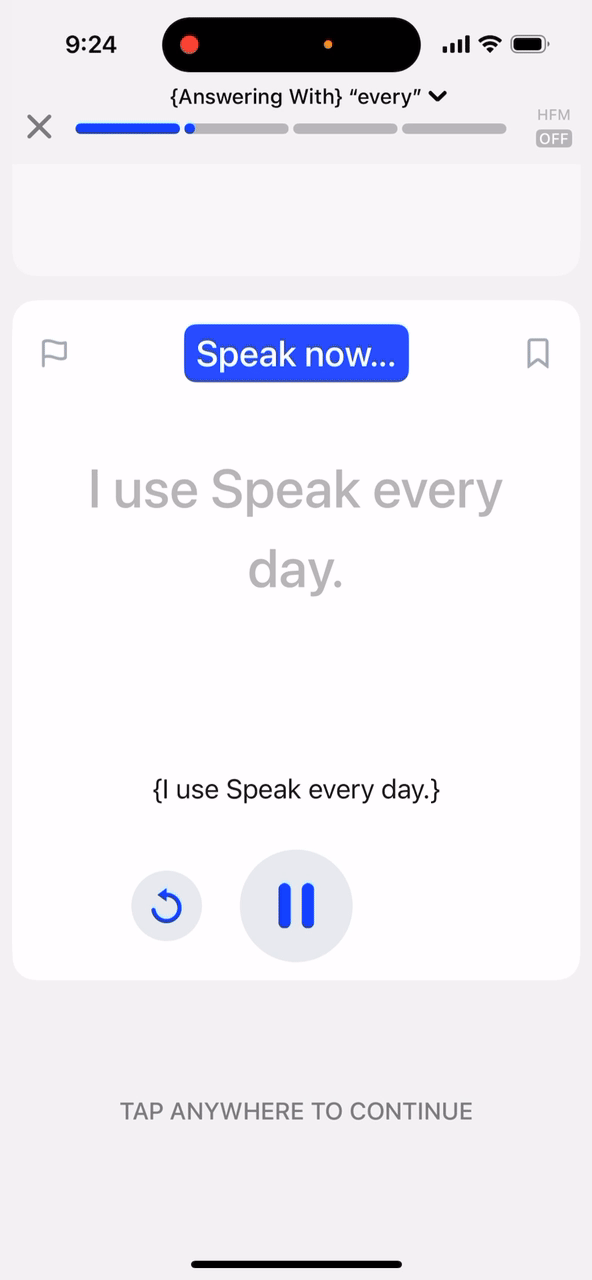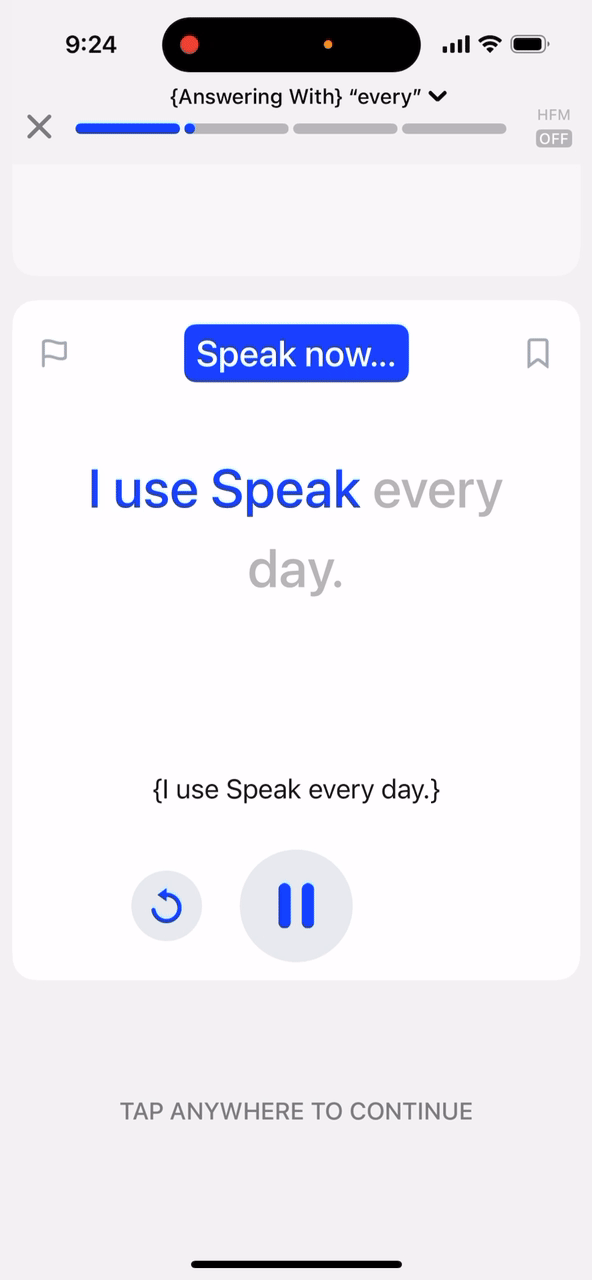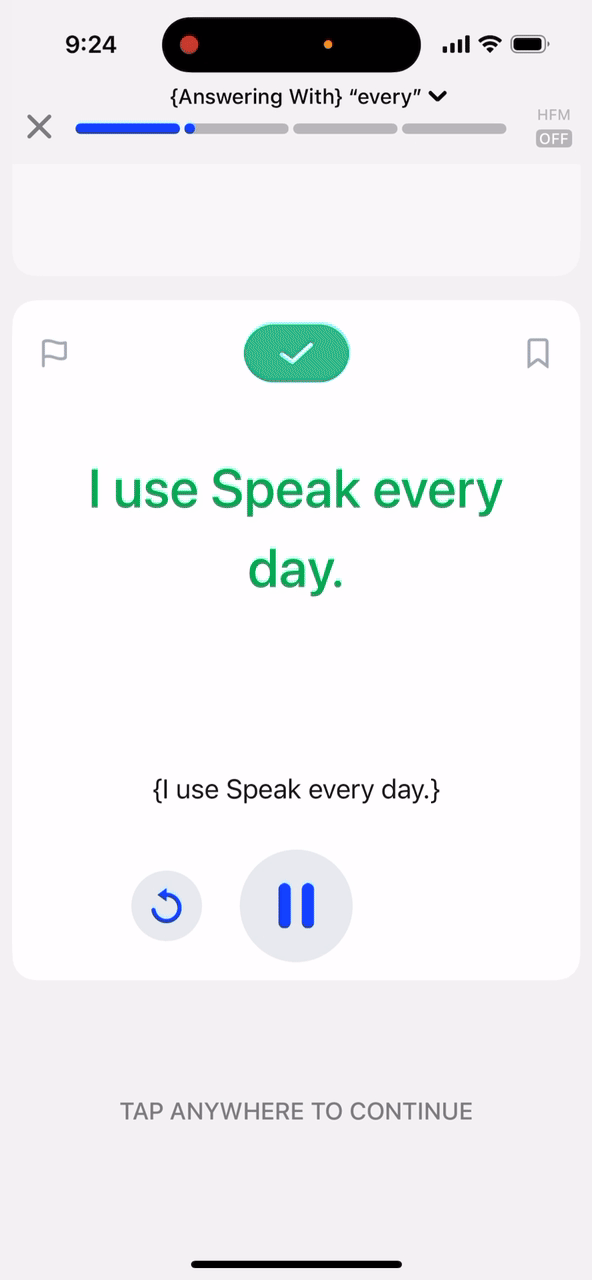
Matching v2를 소개합니다!
우리는 미봉책이나 ASR 모델의 점진적인 개선에 집중하는 대신, 한 걸음 물러서서 매칭 접근 방식을 전면적으로 재검토했습니다.
음성 전사 (Phonetic Transcription)
매칭 v1에도 기본적인 형태의 음성 매칭이 포함되어 있었지만, 이는 텍스트 기반이자 언어 별로 특화된 솔루션이었습니다. 더구나 ASR 모델의 뒷단(downstream)에 위치했기 때문에, 전사 과정에서 발행하는 어떤오류를 보정할 수 없었습니다.
Matching v2에서는 표준 ASR 모델과 함께 음성 모델(Phonetic Model)을 추가했습니다. 이 모델은 "단어로 전사하는" 단계를 완전히 건너뛰고, 사용자의 발화를 언어에 구애받지 않는 국제 음성 기호(IPA, International Phonetic Alphabet) 시퀀스로 직접 변환합니다. IPA는 말소리를 직접 표기하기 위해 고안된 문자 체계입니다. 이론적으로 IPA를 아는 사람은 해당 언어를 모르더라도 IPA만 보고 소리 내어 읽을 수 있습니다. 다양한 다국어 데이터셋으로 훈련된 음성 모델을 사용함으로써, 이 접근 방식은 현재 우리가 가르치고 있는 언어는 물론, 앞으로 가르칠 모든 언어에 즉시 적용될 수 있습니다.
앞서 언급한 "four candles / fork handles" 동음이의어 문제를 다시 예로 들어보겠습니다. 이 두 문구는 IPA로 다음과 같이 전사됩니다.
- four candles:
/fɔɹ kændləz/ - fork handles:
/fɔɹk hændləz/
이제 ASR 전용 접근 방식이 왜 어려움을 겪었는지 알 수 있습니다. 두 문구는 거의 정확히 같은 소리를 포함하고 있으며, 단어의 끊어 읽기 위치와 "fork handles"의 미세한 "h" 소리(기술적으로는 "candle"의 /k/ 발음에 포함된 기식음 형태일 수 있음)로만 구분됩니다. ASR 모델은 둘 중 어떤 문구를 출력할지 무작위로 선택해야 하며, 필연적으로 때때로 틀린 추측을 하게 됩니다. 반면, 음성 모델은 두 문구 간의 유사성을 명확하게 포착합니다.
다시 Matching v2로 돌아와서 보면, 사용자의 발화에 대한 음성 전사(IPA)가 준비되면, 우리는 강제 정렬(forced alignment) 알고리즘을 사용하여 목표 문장의 IPA 전사와 음성 모델의 출력을 정렬합니다. 강제 정렬은 두 시퀀스를 수학적으로 최적화하여 가능한 한 많은 문자가 일치하도록 짝을 짓는 알고리즘입니다. 마지막으로, ASR 전사와 음성 전사를 모두 사용하여 어떤 단어를 매칭 처리할지 결정합니다.
ASR과 음성 전사를 결합함으로써 우리는 두 가지 장점을 모두 취할 수 있습니다.
ASR 모델 (특히 비원어민 발화에 미세 조정된 스픽의 모델)은 가장 가까운 유효한 단어를 출력합니다. 이는 사용자의 발음이 완벽하지 않더라도 사용자가 의도했던 단어일 확률이 높습니다. 음성 모델은 사용자가 실제로 낸 소리를 정확하게 포착하여 차용어, 동음이의어, 약간 잘못된 발음 등의 예외 케이스를 처리하는 데 도움을 줍니다.
순차적 매칭 (Sequential Matching)
매칭 v2의 또 다른 큰 업그레이드는 바로 "Bag of words" 방식을 사용하지 않는다는 것입니다! 이제 카드를 완료하려면 화면에 나타난 순서대로 목표 문장의 단어를 말해야 합니다.
이는 학습 중인 언어의 올바른 어순을 강화하는 데 도움이 되며, 매칭 정확도 또한 높여줍니다. 매칭 가능한 단어의 범위를 전체 목표 문장에서 가장 최근에 매칭된 단어 주변의 하위 집합(subset)으로 좁힘으로써 정확도가 크게 향상되었습니다.얼마나 빨라야 할까요?
실시간 매칭의 과제 중 하나는 모델의 추론 속도입니다. 사용자의 말하기 속도를 따라잡을 만큼 오디오를 빠르게 처리해야 할 뿐만 아니라, 스트리밍을 지원해야 합니다. 즉, 오디오 파일이 끝날 때까지 기다리는 것이 아니라, 오디오 청크(chunk)가 들어오는 대로 반복적으로 처리하여 가능한 한 빠르게 전사 결과를 반환해야 합니다.
전통적인 Kaldi 스타일의 모델은 매우 느려서 스트리밍 모드에서 작동하지 않거나 정확도가 현저히 떨어지는 경향이 있습니다. 그러나 최신 Transformer 기반 모델(ChatGPT와 같은 거대 언어 모델의 기반이 되는 아키텍처)은 스트리밍 모드에서도 쉽게 실행될 수 있습니다. 지난 몇 년간의 생성형 AI(GenAI) 애플리케이션 폭발에 힘입어 고도로 최적화된 Transformer 라이브러리들은 번개처럼 빠른 추론 속도를 보장합니다.
우리는 최고의 전사 아키텍처 중 하나인 wav2vec2 오디오 모델 제품군을 음성 모델링 및 스픽의 매칭 알고리즘에 맞게 커스터마이징했습니다. 이를 통해 정확한 전사와 빠른 스트리밍 추론이라는 두 마리 토끼를 모두 잡을 수 있었습니다.
Matching v2 측정 방법
Speak 외에는 이와 같은 매칭 작업을 수행하는 곳이 거의 없기 때문에, 이 작업을 측정하기 위한 업계 표준 지표는 존재하지 않습니다.
전사(Transcription)의 표준 평가 지표는 영어처럼 띄어쓰기로 텍스트를 구분하는 언어의 경우 단어 오류율(WER, Word Error Rate)이고, 일본어나 중국어처럼 띄어쓰기가 없는 언어의 경우 문자 오류율(CER, Character Error Rate)입니다. WER/CER은 모델 성능을 확인하기 위해 추적하는 지표 중 하나이지만, 이것이 모든 상황을 설명해 주지는 못합니다. 우선, 대부분의 벤치마크 데이터셋은 원어민에게서 나왔다고 가정하지만, 스픽의 사용자는 모든 수준의 유창성과 전 세계의 다양한 억양을 가진 학습자들이기 때문입니다.
스픽의 관점에서 실제로 중요한 것은 "사용자가 자신의 의도를 전달할 만큼 충분히 명확하게 말했는지를 우리가 올바르게 판단하고 있는가"입니다. 이를 확인하는 가장 좋은 방법은 전체 매칭 프로세스의 종단간(end-to-end) 성능을 추적하는 것입니다. 즉, 사용자의 발화부터 화면상의 매칭/비매칭 하이라이트 표시까지의 과정을 보는 것이죠. 여기서 관심 있는 두 가지 범주는 다음과 같습니다.
- 거짓 부정 (False negatives): 사용자가 올바른 소리를 냈지만 화면에서 단어가 초록색(매칭 성공)으로 바뀌지 않는 경우.
- 거짓 긍정 (False positives): 사용자가 제대로 말하지 않았음에도 단어가 초록색으로 바뀌는 경우.
다시 말해, 매칭 알고리즘을 더 엄격하게 만들면 거짓 부정은 늘어나고 거짓 긍정은 줄어들며, 더 관대하게 만들면 그 반대 현상이 나타납니다. 이러한 거짓 부정과 거짓 긍정 사이의 트레이드오프(tradeoff)는 거의 피할 수 없으며, 이는 이곳뿐만 아니라 거의 모든 분류 작업에서 마찬가지입니다. 하지만, 알고리즘 자체를 더 나은 것으로 교체한다면 다른 한쪽의 오류율에 영향을 주지 않으면서 한쪽의 오류를 줄이는 것이 가능할 수도 있습니다. 이것이 바로 개선 작업의 궁금인 목표(holy grail)'입니다! 아래에서 보시겠지만, 우리는 이것을 해냈습니다.
결과
앞서 언급했듯이, 거짓 긍정을 늘리지 않으면서 거짓 부정을 줄이는 것은 매우 드문 성과입니다.
하지만 스픽은 해냈습니다! ASR 모델과 함께 음성 모델을 도입함으로써, 알고리즘을 더 관대하게 만들지 않고도(즉, 거짓 긍정 비율을 그대로 유지하면서) 거짓 부정을 약 40% 감소시켰습니다.
이 그래프는 가장 높은 정확도를 위해 사람이 직접 라벨링(표시)한 실제 사용자 데이터의 내부 테스트 데이터 세트에서 오인식(False negatives)이 감소한 정도를 보여줍니다.

다시 말해, Matching v2를 통해 사용자가 발음이 맞는데도 매칭이 안 되어 곤란을 겪는 경우는 훨씬 줄어들 것입니다. 동시에 단어가 하이라이트 되면 내 발음이 이해될 만큼 명확했다고 생각하는 사용자의 신뢰도 유지할 수 있게 되었습니다.
다음 단계는?
Matching v2는 단순한 기능 개선이 아니라, 스픽이 언어 학습을 어떻게 정의하고 있는지를 보여주는 기술적 선언에 가깝습니다.
우리는 “말했는지 안 했는지”를 판별하는 것을 넘어, 학습자가 실제로 전달하고자 한 의도와 발화의 명확성을 공정하게 판단하는 것을 목표로 삼고 있습니다.
이번에 구축한 음성·매칭 시스템은 앞으로 스픽이 가르칠 모든 언어의 기반이 될 뿐만 아니라,
새로운 언어를 더 빠르고 안정적으로 확장할 수 있는 공통 인프라 역할을 하게 될 것입니다.
또한 향후에는 발음 교정, 더 정교한 피드백, 문맥 기반 학습 경험으로까지 확장될 수 있는 여지를 열어두고 있습니다.
스픽의 기술적 선택과 제품 결정은 언제나 하나의 질문에서 출발합니다.
“이 기술이 정말 학습자의 말하기 경험을 더 나아지게 만드는가?”
Matching v2는 그 질문에 대한 현재까지의 가장 정교한 답변입니다.
스픽이 기술로 풀고자 하는 더 큰 이야기가 궁금하다면
스픽은 단순한 영어 학습 앱이 아니라,
기술을 통해 언어 교육의 본질적인 문제를 다시 정의하려는 팀입니다.
스픽 창업자가 왜 영어 교육을 다시 만들고자 했는지,
그리고 AI와 소프트웨어를 통해 어떤 방향의 학습 경험을 그리고 있는지는
아래 오픈AI 블로그에 소개된 인터뷰에서 더 깊이 확인하실 수 있습니다.
앞으로도 스픽은 실제 사용자 경험에서 출발한 문제를,
응용 연구와 엔지니어링으로 풀어낸 사례들을 지속적으로 공유할 예정입니다.
Share on:
추천 아티클
.png)
.png)


.png)
.png)



